Investigating the impact of model architecture on continual learning performance

Overview
Continual Learning (CL) focuses on enabling models to learn from new data streams over time while preserving past knowledge. Continual Learning seeks to minimize catastrophic forgetting, a critical phenomenon in which deep learning models forget previously trained information upon being training on new data. Online Continual Learning (OCL) evolves this concept by adapting models to learn from ongoing small batches of data in real-time. Online Continual Learning strives for a balance between acquiring new information and retaining old knowledge in dynamic environments.
This study investigates the impact of model size on online continual learning performance and forgetting, using the SplitCIFAR-10 continual learning benchmark. I trained and evaluated ResNet architectures of varying sizes and widths to examine how network size affects model performance in an online continual learning setting (class-incremental learning).
Key findings show that larger models do not necessarily guarantee better continual learning performance; in fact, they often struggle more in adapting to new tasks, particularly in online settings. These results challenge the existing notion that larger models inherently mitigate catastrophic forgetting, highlighting the nuanced relationship between model size and continual learning efficacy. This study contributes to a deeper understanding of model scalability and its practical implications in continual learning scenarios.
Key Findings
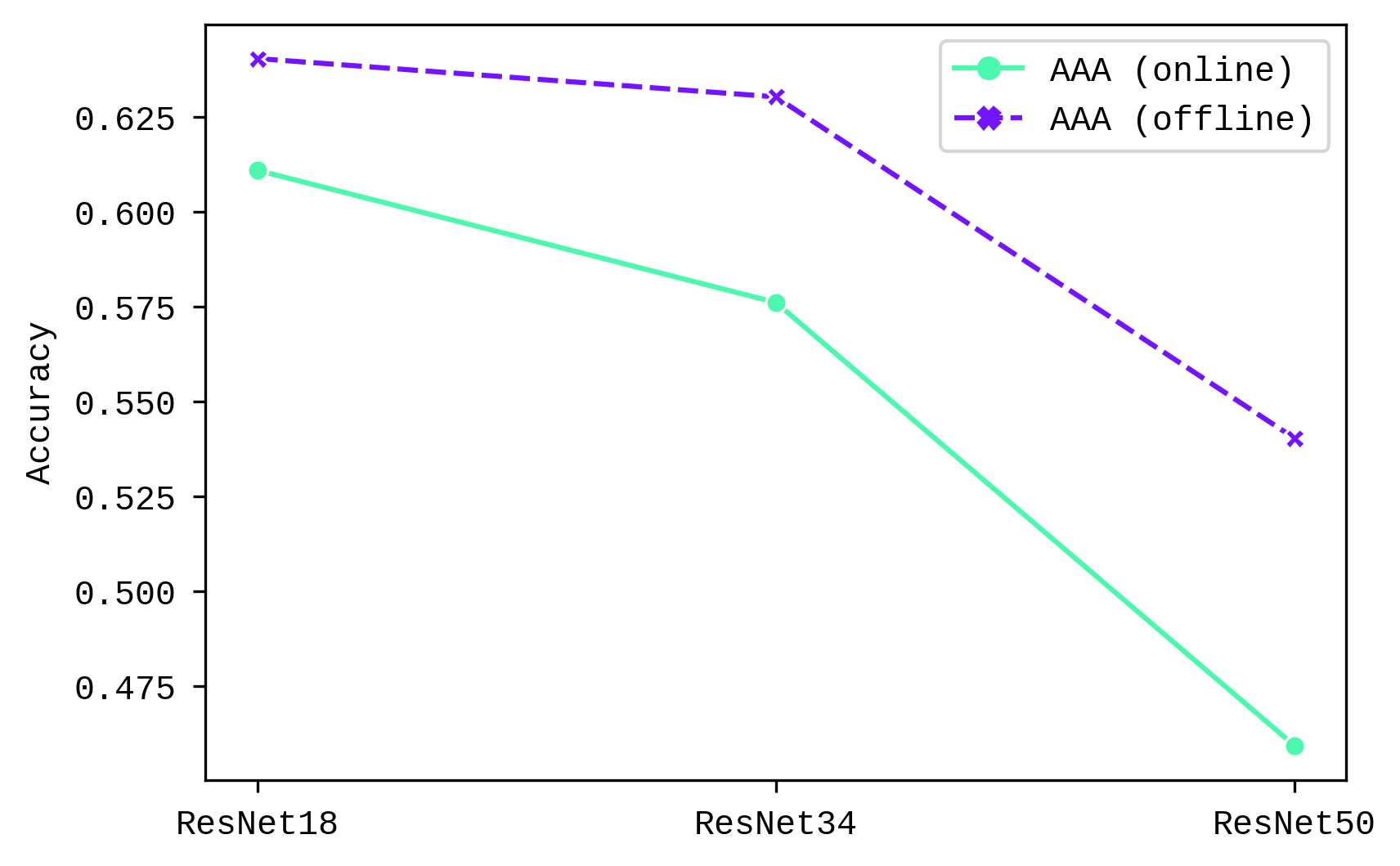
Average Anytime Accuracy (AAA) measures the effectiveness of the model across all stages of training, rather than at a single endpoint, offering a more comprehensive view of its learning trajectory.
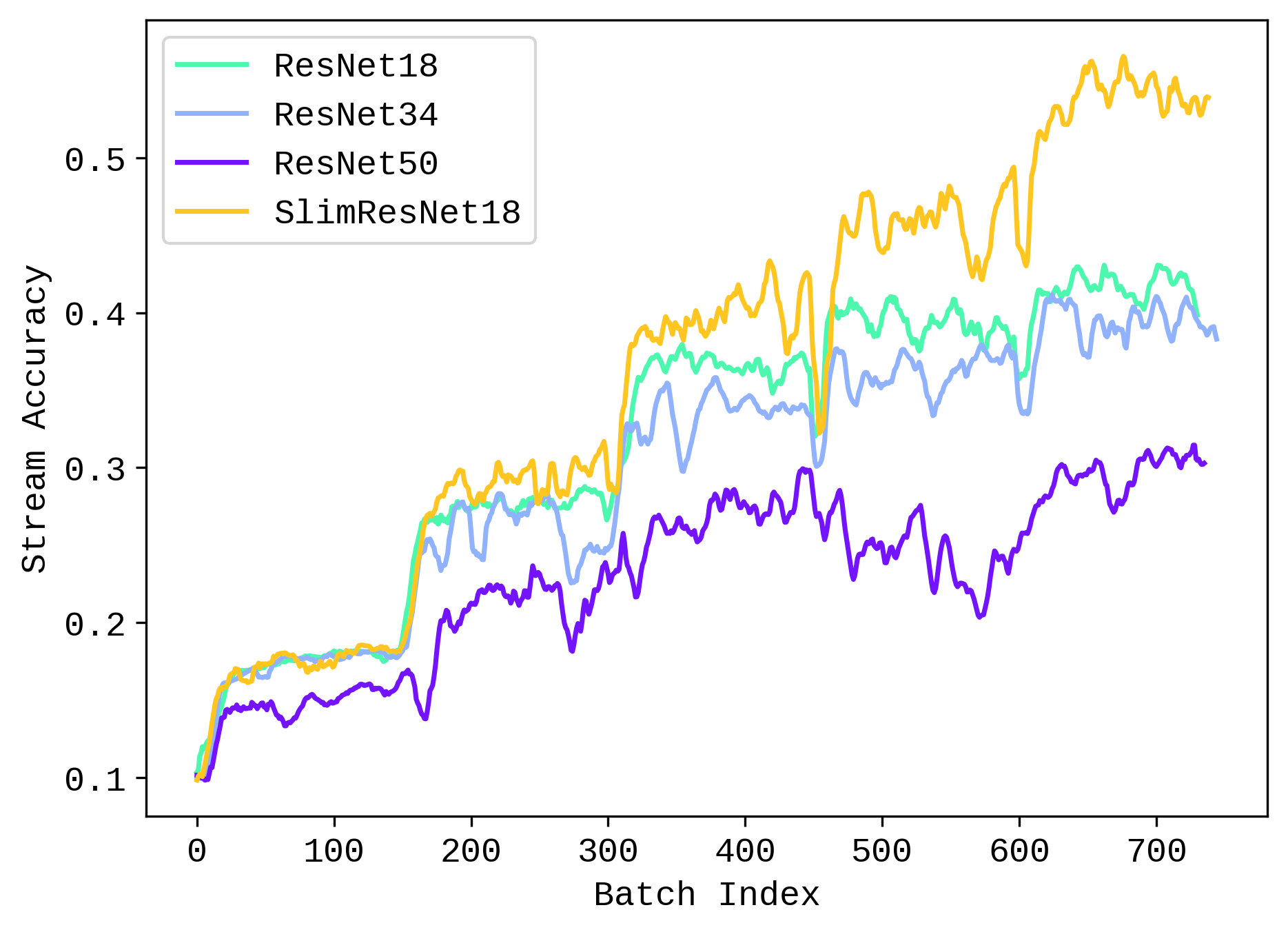
The rate to which validation stream accuracy increases with each task degrade with larger models. Slim-ResNet18 shows the highest accuracy and growth trend. This could indicate that larger models are worse at generalizing to a class-incremental learning scenario.
This differences in forgetting between online and offline CL setting is aligned with the accuracy metrics earlier, where the performance of ResNet50 decreases more starkly in the online CL setting. Future studies could increase training cycles to lead to more insights.
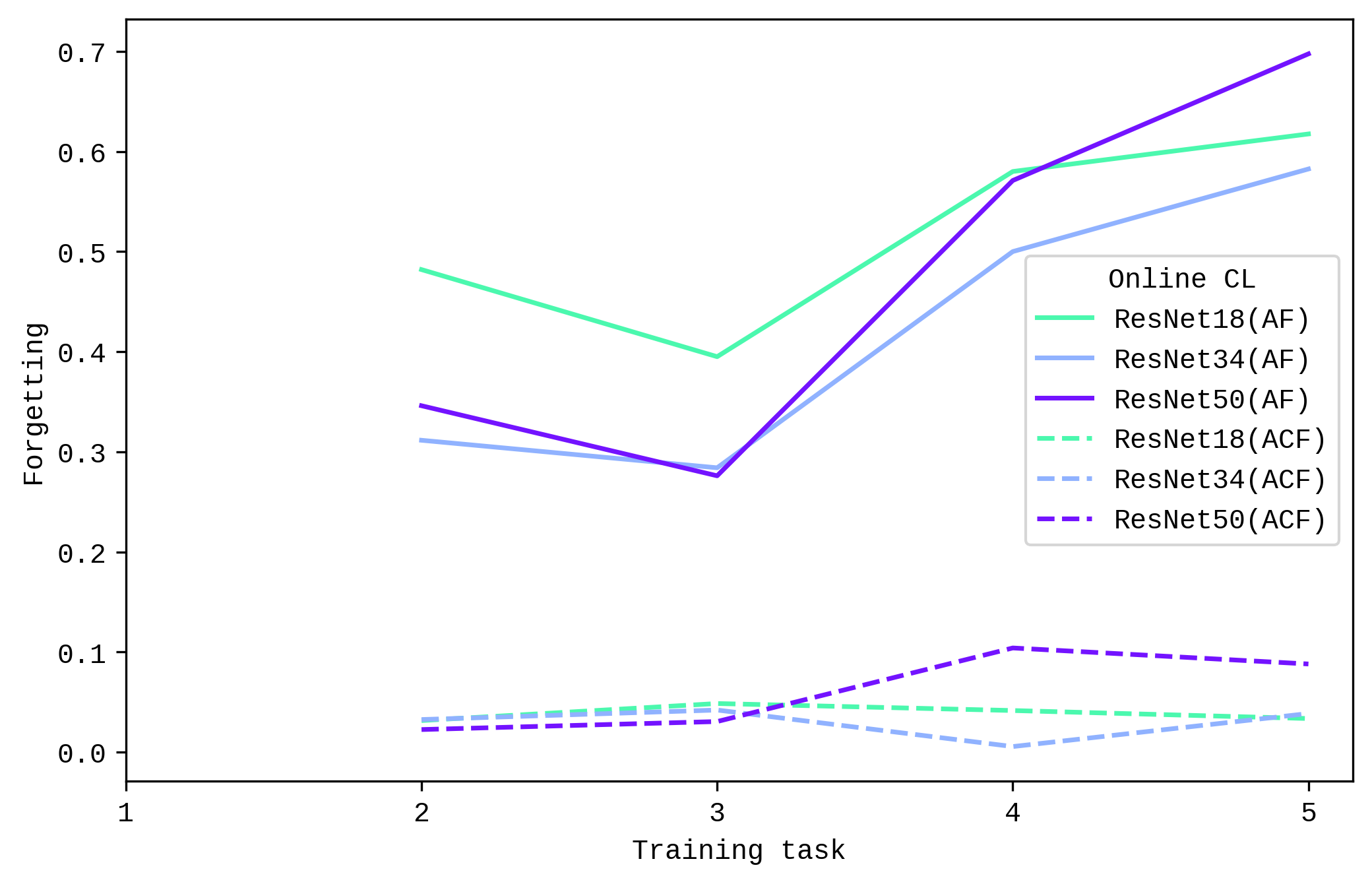
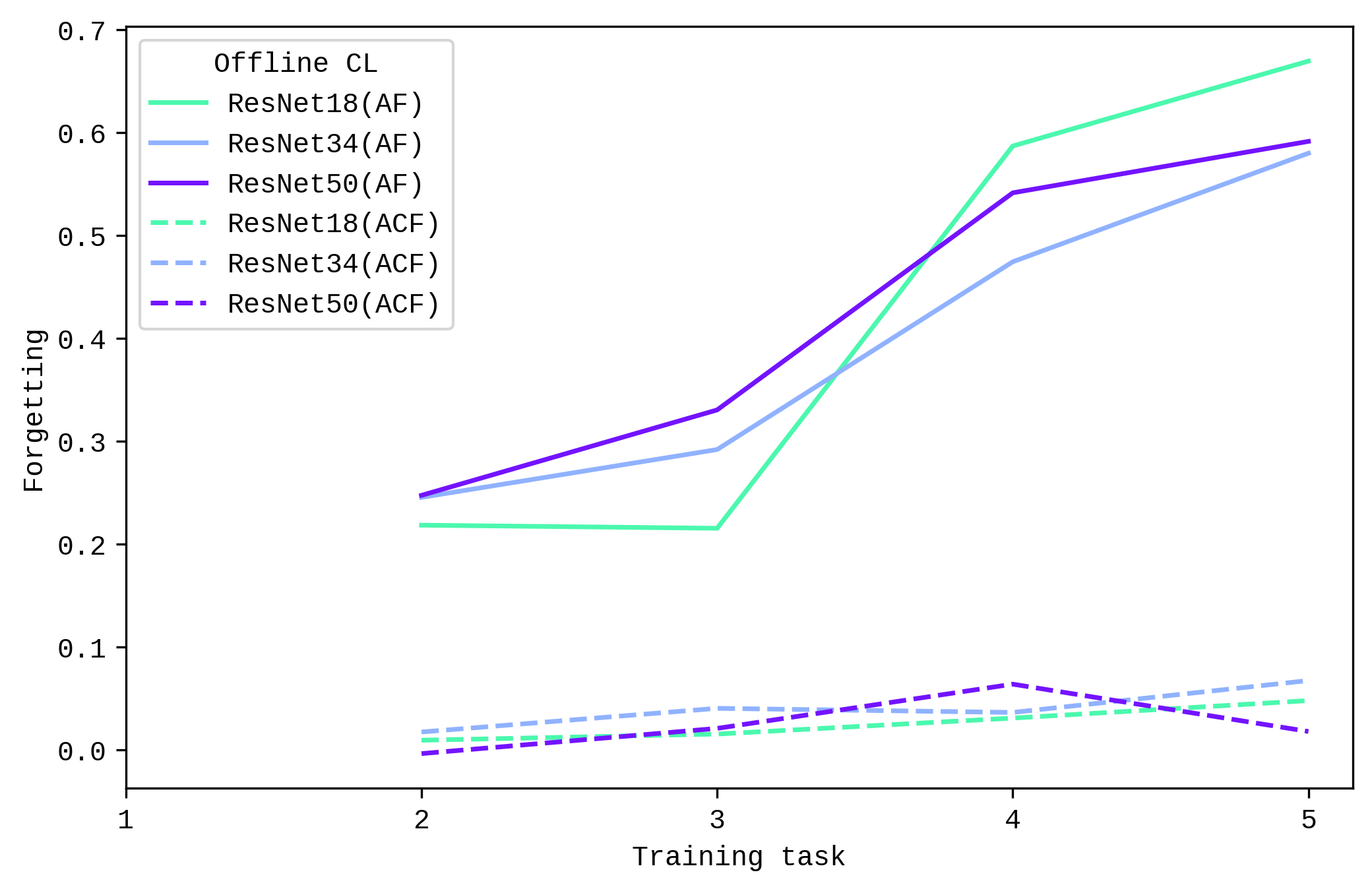
When it comes to the ability to highlight intuitive areas of interest in the images, there seemed to be a noticeable improvement from ResNet18 to ResNet34, but this was not necessarily the case from ResNet34 to ResNet50.

Details
- When: Fall 2023
- This study was completed as a final project for the graduate course 6.S898 Deep Learning at MIT.